使用python的requests包执行网络请求非常方便,可以便利地设置headers、cookies以及请求数据。根据多年使用requests包的经验,以及最近给一个客户的写的代码,下面总结出该包的最佳实践方式。
整体的结构
def read_header_file(header_path):
# 加载代码
if __name__ == '__main__':
s = requests.Session()
read_header_file(header_path)
# 执行请求,无论是get或者post,则无需再设置headers和cookies
s.get('<url>')
headers以及cookies的获取
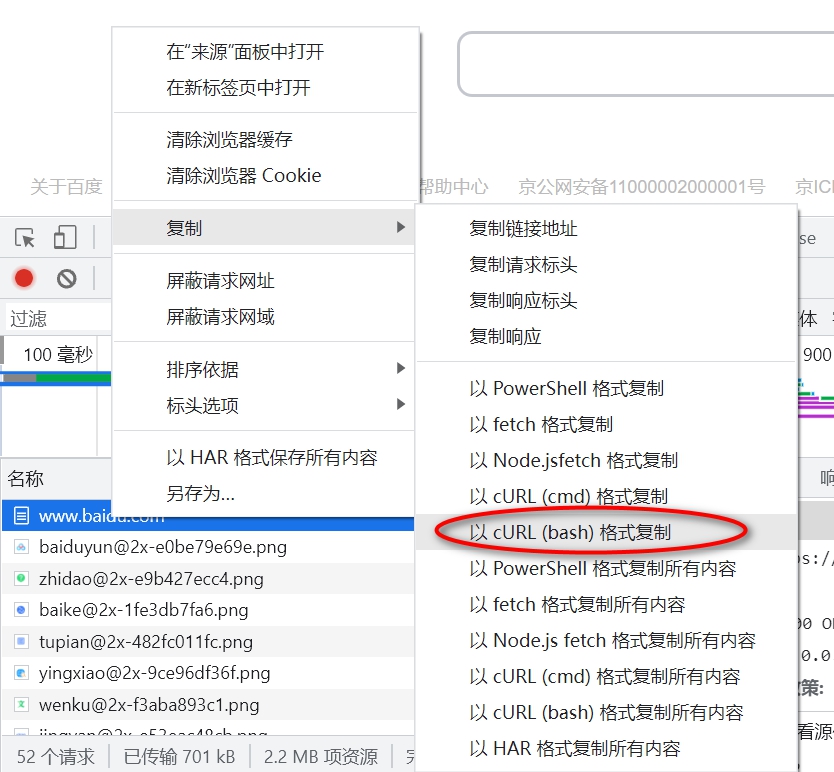
如果使用chrome浏览器,则按F12键后可以调出浏览器的开发工具,然后按照下图所示的方式可以获取到请求的headers和cookies,将其保存为一个文件。
如果对于cookies的要求细节比较多,那么可以在chrome浏览器中安装EditThisCookie插件,然后按照如下图的方式获取Json格式的cookies。
加载headers和cookies
import pandas as pd
def read_header_file(header_path):
df = pd.read_csv(header_path, skiprows=1, skipfooter=1,
header=None, engine="python", sep=r"\s*'\s*", usecols=[1])
for _, r in df.iterrows():
v = r.values[0]
if 'cookie' in v.lower():
jc = v.split(': ', 1)
for kv in jc[1].split(';'):
s.cookies.update(dict([kv.split('=', 1)]))
else:
s.headers.update(dict([v.split(': ', 1)]))
其中header_path变量指的就是之前保存的bash格式的请求文件。
pandas中的read_csv函数非常强大,可以非常方便将一些没有结构化的数据转换成结构化数据。dict函数可以将类似[[a, b]]转换成字典。或者结合for...in...语句,将更多偶数的列表转换成字典。
# INPUT: a = [1, 2, 3, 4]
[dict([a[i:i+2]]) for i in range(0, len(a), 2)]
# OUTPUT: [{1: 2}, {3: 4}]